
What’s the Difference Between Search and Recommendation?
Jonathan Stray, Luke Thorburn, Priyanjana Bengani / Oct 16, 2023Luke Thorburn is a doctoral researcher in safe and trusted AI at King’s College London; Jonathan Stray is a Senior Scientist at The Center for Human-Compatible Artificial Intelligence (CHAI), Berkeley; and Priyanjana Bengani is a Senior Research Fellow at the Tow Center for Digital Journalism at Columbia University.

The question of whether there is a meaningful difference between search and recommendation comes up frequently in discussions of platform harms, where recommendation is sometimes said to show people things they didn’t ask for. There are of course differences, but in many ways these types of systems differ in degree, not in kind, so it’s hard to draw a clean line between them – especially the sort of line you’d want when designing regulation.
Both search and recommendation are types of ranking algorithms. These are the systems which filter and order everything in the digital world, reducing it to the scale of human consumption. In this article we’ll map out dozens of real-world ranking products and features along five axes. These are:
(1) the explicitness of the ranking signals,
(2) the degree of personalization,
(3) the explore-exploit tradeoff,
(4) the openness of the inventory, and
(5) the balance between engagement and content signals.
We’ll pay particular attention to the many systems that fall “in the middle” and confound clean distinctions. For instance, YouTube has a search bar and recommendations on the homepage, but it also lists related videos after the user has already clicked on something, which is somewhere between the explicit query of search and the query-free operation of the homepage.
Grappling with this complexity is important because consequential decisions — such as those relating to legal liability or auditing requirements — can hinge on how ranking systems are categorized. For example, in the recent US Supreme Court case Gonzalez v Google, the plaintiffs argued that search engines are different from recommender systems because they “only provide users with materials in response to requests from the users themselves.” But in amicus briefs to the Court, several parties argued that no clear line can be drawn between the two.
While social media users may not explicitly enter search terms when viewing a feed, the underlying recommender system effectively conducts a search based on a combination of previous user actions and the current context. There are many ways a user might “ask for” content, such as following accounts, joining groups, or navigating to particular topics or channels, and this information often feeds into recommender systems. Meanwhile, search results are often personalized based on the system’s best guess of what the user wants. Because of this ambiguity, interpreting laws that hinge on whether someone “asked” to see something is tricky.
[Consider] just a regular search engine … you put in a search and something comes back, and in some ways, you know, that’s one giant recommendation system.
— Justice Elena Kagan,Transcript of Gonzalez v Google Oral Argument (2023)
Historically, there was perhaps more of a technical difference, with web search using algorithms like PageRank and recommenders using techniques like collaborative filtering. But modern approaches are more alike. At the center, ranking systems have a “value model” or “scoring function” which combines many different types of signals into an overall score for each item to be ranked, and then sorts the items by this measure of value. The boundary is also blurry in academic literature, where both “search” and “recommendation” are included within a larger field of “information retrieval.”
Fundamentally, search and recommendation and everything in between are computational tools to help us manage the allocation of human attention. It’s difficult to imagine navigating the modern world without such systems, but there are personal, social, political and economic consequences to the way these systems work, which is why we will probably always be arguing over how to categorize them for policy purposes. Rather than trying to put everything into either the “search” or “recommendation” box, we have tried to map the space of ranking approaches.
Explicitness of Ranking Signals
It is often said that recommenders are different from search algorithms because they don’t require an explicit prompt from the user, that recommenders show people things that they didn’t explicitly “ask for.” But there are many cases in which “whether you asked for it” is not well defined, and it is more accurate to think of ranking systems as positioned on an axis from those that use entirely explicit signals for ranking (e.g., search terms) to those that rely mostly on implicit signals.
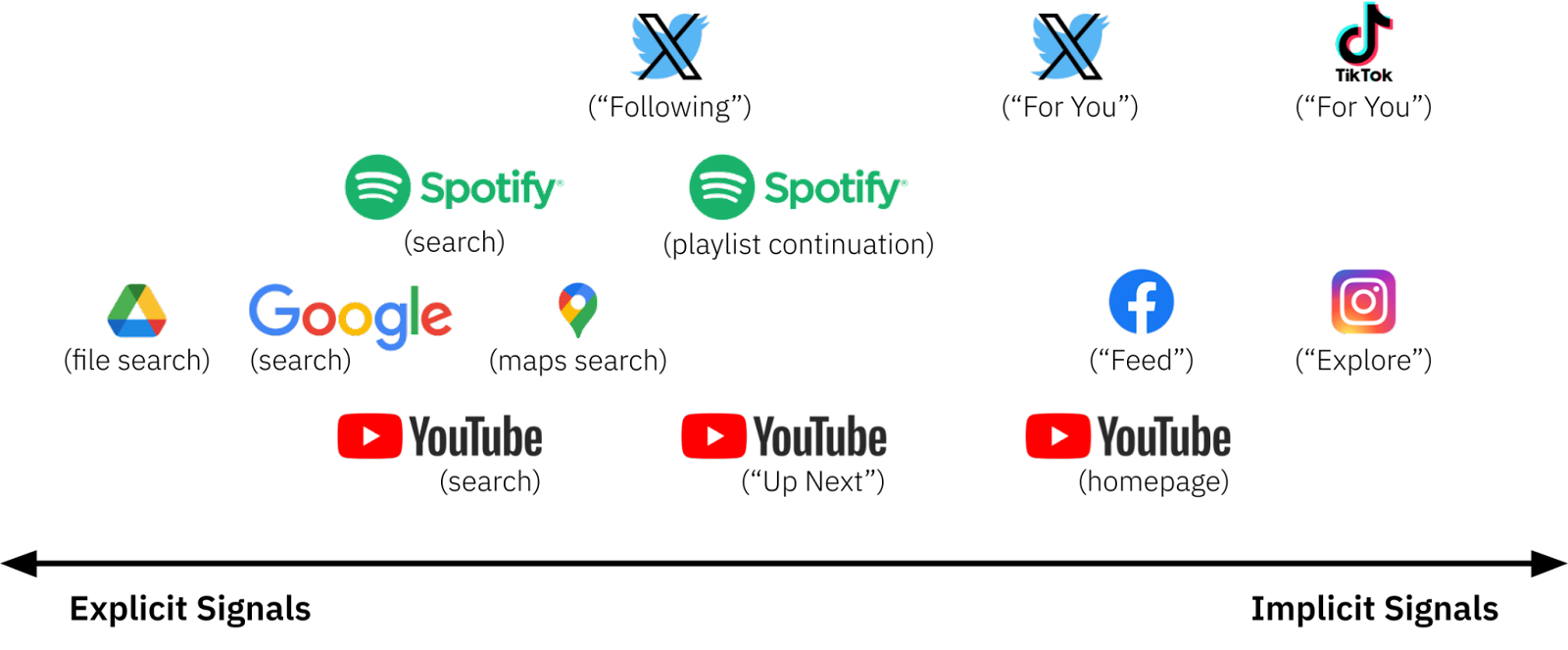
At one end of the axis lie search algorithms, such as file search in Google Drive, that essentially rank items based on the degree to which they match the explicitly-entered search term. At the other extreme, recommenders like the TikTok “For You” feed, or Instagram “Explore”, predominantly use implicitly-collected engagement data such as dwell time.
But many high-profile ranking algorithms lie somewhere in between these extremes. Consider three examples from YouTube: the homepage, “Up Next” videos, and search. All of these algorithms use both explicit signals (e.g., the accounts you subscribe to) and implicit signals (e.g., predicted engagement based on your historical engagement data), but weight each type of signal differently.
- YouTube homepage — Mostly based on historical engagement (implicit).
- YouTube Up Next — Based on both historical engagement (implicit) and the current video (explicit).
- YouTube search — Mostly based on search terms (explicit).
Other examples of ranking algorithms that combine implicit and explicit signals include:
- Google Maps search — Based on both the search terms (explicit) and your location (implicit).
- Spotify playlist continuation — Based on both the songs you added to the playlist (explicit) and predictions about what similar songs you would like (implicit).
These examples show that in many cases it is not clear what it means to “ask for” certain content, which undermines attempts to regulate around a principle that “if people ask for x they should be able to see it, but if they don’t ask for x they shouldn’t be shown it”. There is too much gray area. If you are browsing deep in the Politics podcast category on Spotify and find a podcast by an extremist political group, did you “ask” to see it? If you join a Facebook group in which faulty medical advice is often shared, did you “ask” to see it?
Even search interfaces (where people do explicitly “ask” for something) involve a bunch of complex value judgements, whether or not the system designers are aware of them. If someone searches for advice about abortion, what should you show them? How do you rank products in Amazon search to be fair to different sellers? These are important questions which get obscured by a focus on providing users only what they ask for.
Personalization
A second axis is the degree to which the outputs of a ranking algorithm are personalized. Our focus here is on interest-based personalization, rather than the more generic customization that occurs when tailoring outputs to a large category of users (such as those in a particular region or language community).

At one end of the axis lie highly personalized recommenders such as the TikTok “For You” feed or the suggested files at the top of the root directory in Google Drive. At the other end are ranked outputs that are the same for everyone, such as Wikipedia search results or the ordering of posts within a subreddit.
In between are ranking algorithms that are personalized to varying degrees. These include — perhaps counter-intuitively — search results, which are often personalized and function much like engagement-optimizing recommender systems. This is true of search algorithms on YouTube, Facebook and X (formerly Twitter). LinkedIn tries to guess your intent (e.g. “content consuming”, “job seeking”, or “hiring”) and uses this information, along with information from your connections, to personalize search results. Search engines including Google also personalize some results (and have done since at least 2009). While such personalization sparked early concern about filter bubbles, much of this is fairly innocuous. For example, when you search for a trade such as “plumber,” Google will use your location to return businesses that are in your area.
Explore-Exploit Tradeoff
A third axis captures the degree to which a ranking algorithm engages in exploitation (giving users what it already knows they want) versus exploration (giving users new things, sometimes randomly, to find out if they like them). The amount of exploration is closely related to the concepts of diversity and serendipity in recommender systems, both of which have been widely studied.

Most recommenders sit somewhere in the middle of the axis. For example, the TikTok “For You” feed and the YouTube homepage will try to strike a balance between exploration and exploitation, recommending content they can confidently predict you like, but also more diverse, exploratory recommendations to discover new interests. In contrast, search algorithms like Google Search are weighted mostly towards exploitation, assuming the user knows what they are looking for.
Social media platforms often provide versions of their recommenders that are deliberately more exploratory, such as the Instagram “Explore” feed or the YouTube “New to you” recommendations. Amazon’s “Based on your history” recommendations are at the other extreme, heavily exploiting knowledge of what products you have recently viewed. Spotify tries to personalize the explore-exploit tradeoff for each user depending on how much diversity they like.
Another example comes from online advertising. The algorithms that choose which alternative ads from the same campaign to show people can be thought of as ranking algorithms, and these tend to change from being highly exploratory early in a campaign (to find out which ads work), to highly exploitative late in a campaign (to maximize sales).
Openness of Inventory
A fourth axis captures whether the inventory — the set of items being ranked — is open, curated, or closed. Can anyone submit anything to be ranked? Or does the inventory only include items vetted or created by the platform?

At one end of the axis are ranking algorithms with inventories that are almost completely open. Anyone can create a web page that appears in Google Search. Anyone with an account can post content on social media platforms like Facebook or X, or on other user-generated content sites like DeviantArt. At the other extreme are ranking algorithms on platforms with completely closed inventories, including The New York Times and BBC iPlayer. These platforms personally commission or create the content they host.
In the middle lie news recommenders such as Google News and The Factual, which will only include items they classify as news content, perhaps only from a curated list of domains known to be associated with news media organizations. Recommenders on platforms such as Audible, Spotify, or the AppStore are also somewhere in the middle — they are open, but it takes a bit of effort to satisfy the platform requirements and submit your content. Sometimes open platforms can also give the impression of being exclusive and closed (think podcast recommendations in Apple Podcasts) because content without any accrued reputation is so heavily downranked that it is never seen.
Content versus Engagement
A fifth axis describes the relative weight a ranking algorithm gives to two kinds of information: semantic information about the content, and information about the behaviors or engagement it tends to generate.

At one end lie algorithms which rank items based solely on the properties of the content itself. A good example of this is The Factual, a recommender which ranks news articles based on their tone and the reliability of their publisher,author and sources, without using any popularity, voting, or engagement feedback. At the other end are engagement-maximizing recommenders such as the TikTok “For You” feed, which ranks videos according to which are most likely to increase behavioral outcomes such as user retention and time spent in the app.
In between lie ranking algorithms — primarily search algorithms — which use a mixture of content and engagement signals. For example, a leaked list of signals used by Russian search engine Yandex includes “text relevance” and whether the content is news (content), but also “how often a given URL is clicked for a given query” (engagement). Certain engagement patterns can also help identify content that people don’t want (e.g., if you click on a search result and then immediately come back, that suggests it wasn’t what you were looking for). Search algorithms on platforms like Netflix and Spotify also use a combination of content and engagement signals, balancing relevance to your query with the probability that you will watch a video or listen to a song.
The Allocation of Attention
Search engines and recommenders are both types of ranking algorithms, and there are all sorts of hybrid forms between them. It is difficult to draw clean lines that make sense as legal distinctions, and in particular, the claim that search is categorically different because it involves users “asking” to see things is too simplistic. Instead of thinking in binary “search vs. recommendation” terms, we encourage policymakers to consider the whole space of possible ranking algorithms. The axes above provide a map of the space that might help to think through the consequences of proposed categorizations.
Beyond discrete rankings, there are many other algorithmic systems that do similar kinds of prioritization, including large language models, reputation systems, and “contextualization engines”. Instead of drawing distinctions between these algorithms, it may be more fruitful to acknowledge that we care about them because they systematically allocate human attention in certain ways, and to consider what standards should be met by the algorithms to which we delegate this responsibility.
Authors



