Studying Underground Market for Large Language Models, Researchers Find OpenAI Models Power Malicious Services
Prithvi Iyer / Jan 19, 2024
Despite the hype around them, readers of Tech Policy Press are well aware that the advance of large language models (LLMs) and their various applications– ranging from chatbots and coding assistants to recommendation systems– has raised various concerns about their misuse. LLMs have been exploited for dangerous purposes like creating false and misleading images, writing malware code, phishing scams, and generating scam websites. However, there is no systematic study exploring the magnitude and impact of their application to various forms of cybercrime.
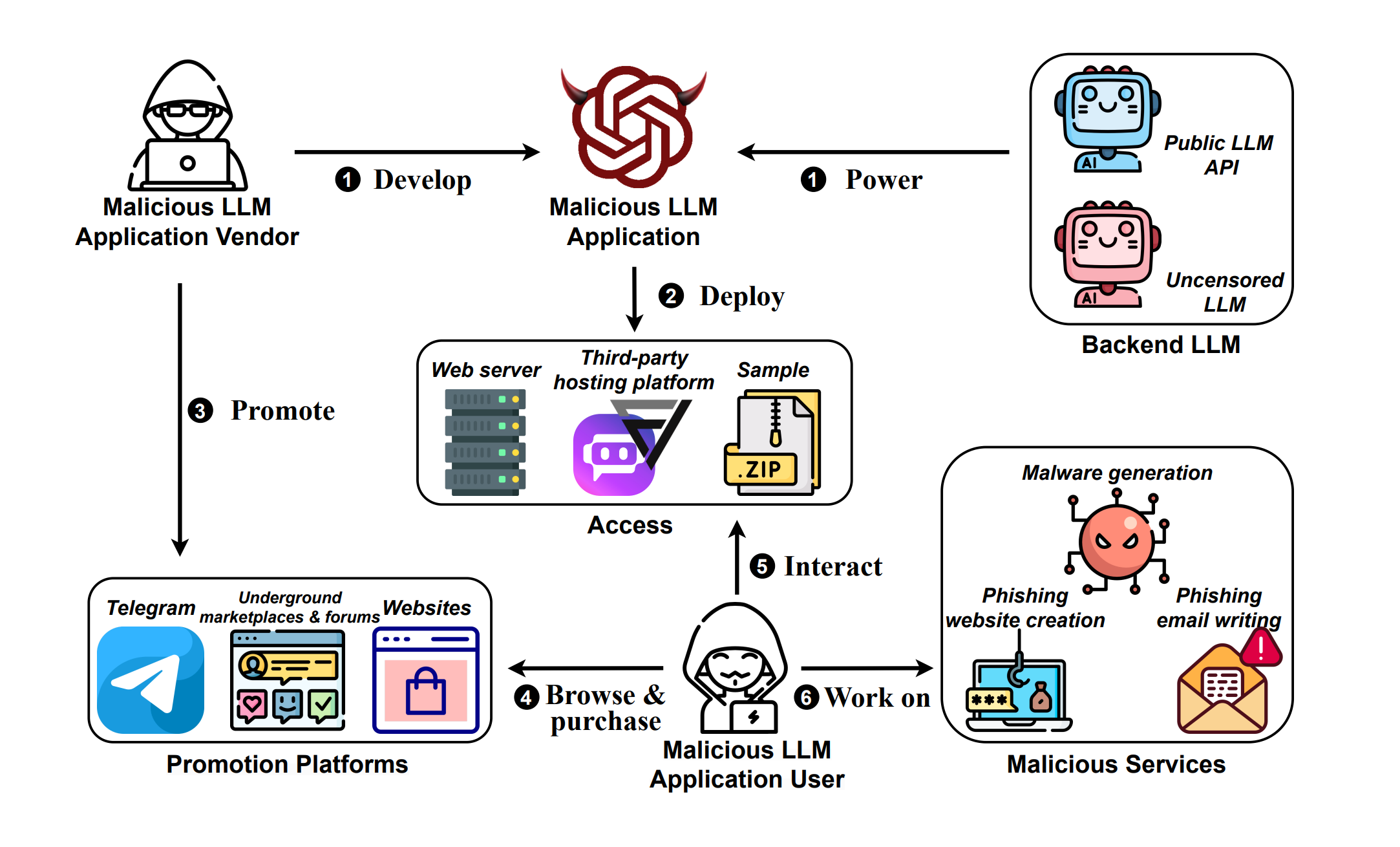
That is, until now. In what the researchers call a first-of-a-kind study, Zilong Lin, Jian Cui, Xiaojing Liao, and XiaoFeng Wang from Indiana University Bloomington examined 212 real-world “Mallas”– their term for LLMs used for malicious services – “uncovering their proliferation and exposing their operational modalities.” The study, titled “Malla: Demystifying Real-world Large Language Model Integrated Malicious Services,” provides a glimpse into the challenges of AI safety while pointing to practical solutions to make LLMs safer for public use. And, it notes the important role that general purpose models– particularly ones developed by OpenAI– play in serving as the backend for tools and services with names like BadGPT, XXXGPT, and Evil-GPT.
Methodology and Findings
For this “systematic study,” the Indiana researchers set out to “unearth the underground ecosystem and the modus operandi” for the malicious use of LLMs. They collected 13,353 listings from nine underground marketplaces and forums– essentially the products and services for sale in venues where black hats gather, such as Abacus Market, Kerberos Market, Kingdom Market, WeTheNorth Market, Hack Forums, BreachForums, and BlackHatWorld– from November 30, 2022 through October 12, 2023.
Through these efforts, they were able to identify various services employing LLMs that are available on the black market along with information on their pricing, functionality, and even demo screenshots. The researchers directly engaged with the vendors of these services and, where possible, obtained complimentary copies of them. In some cases (and with close supervision from the university’s institutional review board), they purchased the services, though notably, some attempts to buy WormGPT, FraudGPT, and BLACKHATGPT were unsuccessful, despite the transfer of bitcoin to the vendors.
Acquiring this devilish bag of tricks allowed the researchers to examine different elements of these malicious services, including what backend LLMs they used, and a collection of “prompt-response pairs related to their malicious capabilities.” They also evaluated how well the software performed. 93.4% of the Mallas examined in the study offered the capability for malware generation, followed by phishing emails (41.5%) and scam websites (17.45%). The malware code generated by EscapeGPT and DarkGPT was the most sophisticated and evaded virus detection. EscapeGPT was the best at creating scam websites, while WolfGPT demonstrated remarkable skill in creating convincing phishing scams.
What backend LLMs are these products and services built on? The researchers observed “five distinct backend LLMs employed by Malla projects, including OpenAI GPT-3.5, OpenAI GPT-4, Pygmalion-13B, Claude-instant, and Claude-2-100k.” According to their research, “OpenAI emerges as the LLM vendor most frequently targeted by Mallas.”
A graphic depicting a Malla workflow. Source
The study further established that Mallas including DarkGPT and EscapeGPT were proficient in “producing high-quality malware that is both compilable and capable of evading VirusTotal detection, while others (e.g., WolfGPT) can create phishing emails with a high readability score and manages to bypass OOPSpam,” a common spam filter. While OpenAI and other LLM vendors have safety checks that include extensive training using human feedback (RLHF) and other moderation mechanisms, the study found that Mallas can circumvent these security measures.
Miscreants seem to be using one of two techniques to misuse LLMs. The first one is exploiting “uncensored LLMs.” The study defines “uncensored” as open-source models with minimal safety checks, allowing users to freely generate content, irrespective of its potential harm. Using such “uncensored LLMs” for malicious services points to the dangers of making such models publicly available without appropriate safety checks. For instance, two Malla services exploited the PygmalionAI model, a refined version of Meta’s LLaMA-13B that has been fine-tuned using data with NSFW content. The trained model, in this case, is free for public use and accessible through platforms like Hugging Face. Using open-source and pre-trained models reduces overhead data collection and training costs, making it more feasible for malicious actors to carry out scams using generative AI.
To make use of models that are not publicly available and have undergone extensive safety checks and red teaming, malicious actors have resorted to jailbreaking. The study found “182 distinct jailbreak prompts associated with five public LLM APIs.” OpenAI’s GPT Turbo 3.5 “appears to be particularly susceptible to jailbreak prompts,” the authors note.
Recommendations
One goal of the research is to “enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.” By examining the threat landscape of malicious actors using LLMs, the authors arrived at concrete recommendations to build safer models that are resilient against bad actors. The dataset of the prompts used to create malware through uncensored LLMs and the prompts that helped bypass the safety features of public LLM APIs is available for other researchers to study. By raising awareness of how such prompts can lead to malpractice, the research can help model developers build safer systems. This study also points to the dangers of “uncensored LLMs,” urging AI companies to “default to models with robust censorship settings” and urging access to uncensored models to be reserved for the scientific community, guided by rigorous safety protocols.
Along with misusing uncensored LLMs, the study shows how bad actors utilize LLM hosting platforms like FlowGPT and Poe to make their services accessible to a broader public. FlowGPT offered unrestricted access to these services without establishing clear usage guidelines. Thus, it is imperative that LLM hosting platforms realize the scope of misuse and proactively establish guidelines and enforcement mechanisms to mitigate the threat posed by Mallas. As the authors note, “this laissez-faire approach essentially provides a fertile ground for miscreants to misuse the LLMs.”

Authors

