
Researchers Explore Partisanship in Twitter Crowdsourced Fact-Checking Program Birdwatch
Justin Hendrix / Apr 6, 2022
In January 2021, Twitter introduced a pilot "community-based approach to misinformation" it dubbed "Birdwatch." The idea is relatively simple- the system allows users to annotate tweets with additional context, and for other users to rate those annotations.
Birdwatch allows people to identify information in Tweets they believe is misleading and write notes that provide informative context. We believe this approach has the potential to respond quickly when misleading information spreads, adding context that people trust and find valuable. Eventually we aim to make notes visible directly on Tweets for the global Twitter audience, when there is consensus from a broad and diverse set of contributors.
In March of this year, Twitter announced it would expand access to the program, which according to TechCrunch has been tested by "a small group of 10,000 contributors who have invested time in writing and rating notes to add more context to tweets that could be potentially misleading."
Twitter provides access to data and code for the program, allowing researchers to evaluate it. A trio of researchers from MIT's Sloan School of Management-- Jennifer Allen, Cameron Martel and David Rand-- used the Notes and Rankings datasets provided by Twitter in combination with a dataset of tweets acquired through the Twitter API to observe the behavior of Birdwatch participants. "Characterizing the behavior of social media user crowds who are allowed to choose what to rate illuminates whether partisanship plays a large role in how users 1) rate the accuracy of others’ content and 2) judge the helpfulness of fact-checks," they write in a preprint available at PsArXiv.
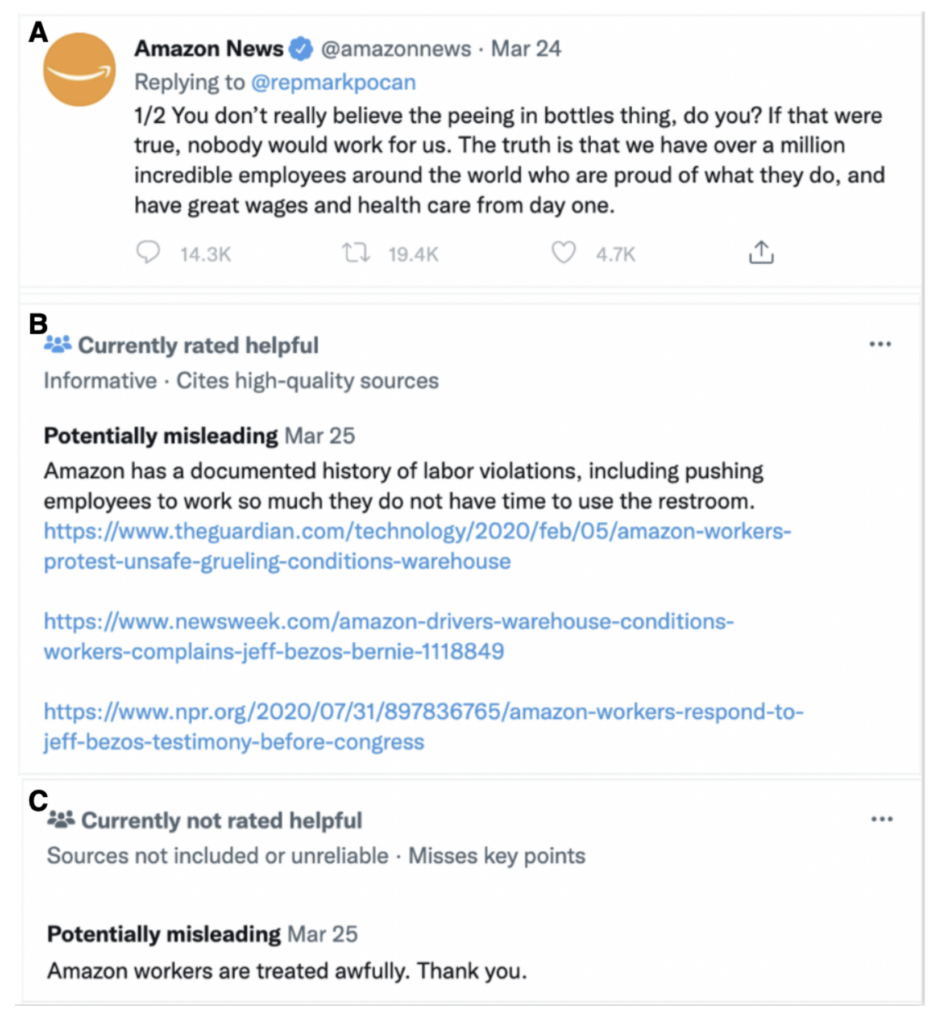
Relying on methods from prior research to assess the partisanship of the Birdwatchers as well as to assess other "features" of "tweet authors, Birdwatch note writers, and Birdwatch note raters," the authors are then able to model the relationship between those features and the inputs people provide to Birdwatch. Their analysis finds that "the interaction between the partisanship of the tweeter and note writer when predicting the misleadingness classifications, and between the note writer and rater when predicting the helpfulness of ratings are both highly significant and large in magnitude."
In other words, "partisanship is an important predictor of how Twitter users evaluate the accuracy of others’ tweets, with content from counter-partisans judged as more misleading and unhelpful than content from co-partisans." So if you are a Democrat, you are more likely to choose to evaluate and judge a Republican's tweet as misleading, and vice versa. This dynamic appears to hold even for non-political content.
Does this mean that Birdwatch is somehow flawed, given that this phenomenon of "partisan selective evaluation" is at play? Not necessarily, the researchers conclude. "Importantly, the preferential flagging of counter-partisan tweets does not necessarily impair Birdwatch’s ability to identify misleading content. It is possible that partisans are successfully identifying misinformation from across the aisle (even if they are not scrutinizing content from their own co-partisans as closely), and/or that aggregating ratings from the entire community cancels out bias from both sides." In a small sample of 57 tweets that Birdwatchers regarded as misleading, 86% were also considered misleading by professional fact-checkers.
The study has interesting implications for Birdwatch as it continues to expand. Might ratings and notes potentially inflame an already polarized political discourse? The authors note that "[p]ublic corrections could also cause backlash from the original tweeter," and they note there are dynamics at play with regard to the Birdwatcher's reputations, as well, which are another factor that affects how their notes are perceived. Ultimately, these dynamics suggest the designers of Birdwatch-- and perhaps other crowdsourced fact-checking systems of the future-- should engineer their systems with these phenomena in mind.
While we do not believe that our findings mean that social media platforms should abandon crowdsourcing as a tool for identifying misinformation, the patterns we observe clearly indicate that it is essential to consider partisan dynamics when designing crowdsourcing systems.
Misinformation and disinformation are an exceedingly complex problem. Crowdsourced solutions may eventually help, but ultimately, "developing such tools will require the collaboration of scholars, technologists, civil society, and community groups," as NYU's Zeve Sanderson and Joshua Tucker wrote in Tech Policy Press last year. This study is another clarifying contribution to that effort.
Authors

