Language Models Trained on State Media Sources Launder Propaganda
Justin Hendrix / May 13, 2026
The outputs of Large Language Models (LLMs) are shaped by the data they are trained on, and the evidence is clear that they do not behave neutrally across all languages and subject matter as a result. As more and more people rely on chatbots and other AI systems to get news and information, understanding how the results they produce may be influenced by their training data and other constraints placed on them is a subject that researchers and journalists are keen to understand.
Now, a new article published in Nature sheds new light on how state media control can influence LLM outputs, with a particular focus on China. The results—from researchers at the University of Oregon, Purdue University, the University of California San Diego, New York University, and Princeton—suggest that investments in state-run media are paying dividends in the age of AI.
As NewsGuard editor for AI and foreign influence McKenzie Sadeghi noted in Lawfare last year, the models “powering today’s most widely used chatbots have been exposed to a polluted information ecosystem where state-backed foreign propaganda outlets are increasingly imitating legitimate media and employing narrative laundering tactics optimized for search engine visibility—often with the primary purpose of infecting the AI models with false claims reflecting their malign influence operations.” In the Nature article, the researchers note that “state control of the media in many countries is already reflected in the training data of common commercial LLMs and is currently influencing the responses of these models.”
This is problematic, they say, because the process that renders outputs for users “severs information and opinion from their source, effectively laundering government-manipulated content into ostensibly objective text.” The article recounts the results of six studies examining phenomena such as how “writing scripted by China’s Publicity Department appears with substantial frequency in common open-source multilingual training datasets,” and how widely used LLMs “have memorized writing distinctive of Chinese state-scripted and state-curated media content.” In one study, the researchers looked at how OpenAI’s GPT 3.5 generated responses related to China, finding that when prompts are given in Chinese, the results are “substantially more favourable towards China” than when the model is prompted in English.
Using their understanding of the “mechanism” these studies expose, the researchers conducted a sixth study to look for implications in a set of 37 nations where “70% of speakers of a particular language live in that country.” They found that, among these nations, “those with more state media control have more favourable portrayals of the regime from LLMs queried in the country’s language.” The researchers suspect this is a product of how models are trained, not a direct effort at manipulation, but nevertheless say that the result “raises the concern that states might strategically exploit pathways to model influence through training data in the future.”
Utilizing scores from the World Press Freedom Index (WPFI), which measures media freedom, the researchers “found that countries with more state media control are more likely to produce pro-regime responses in their official language versus in English than countries with greater media freedom.”
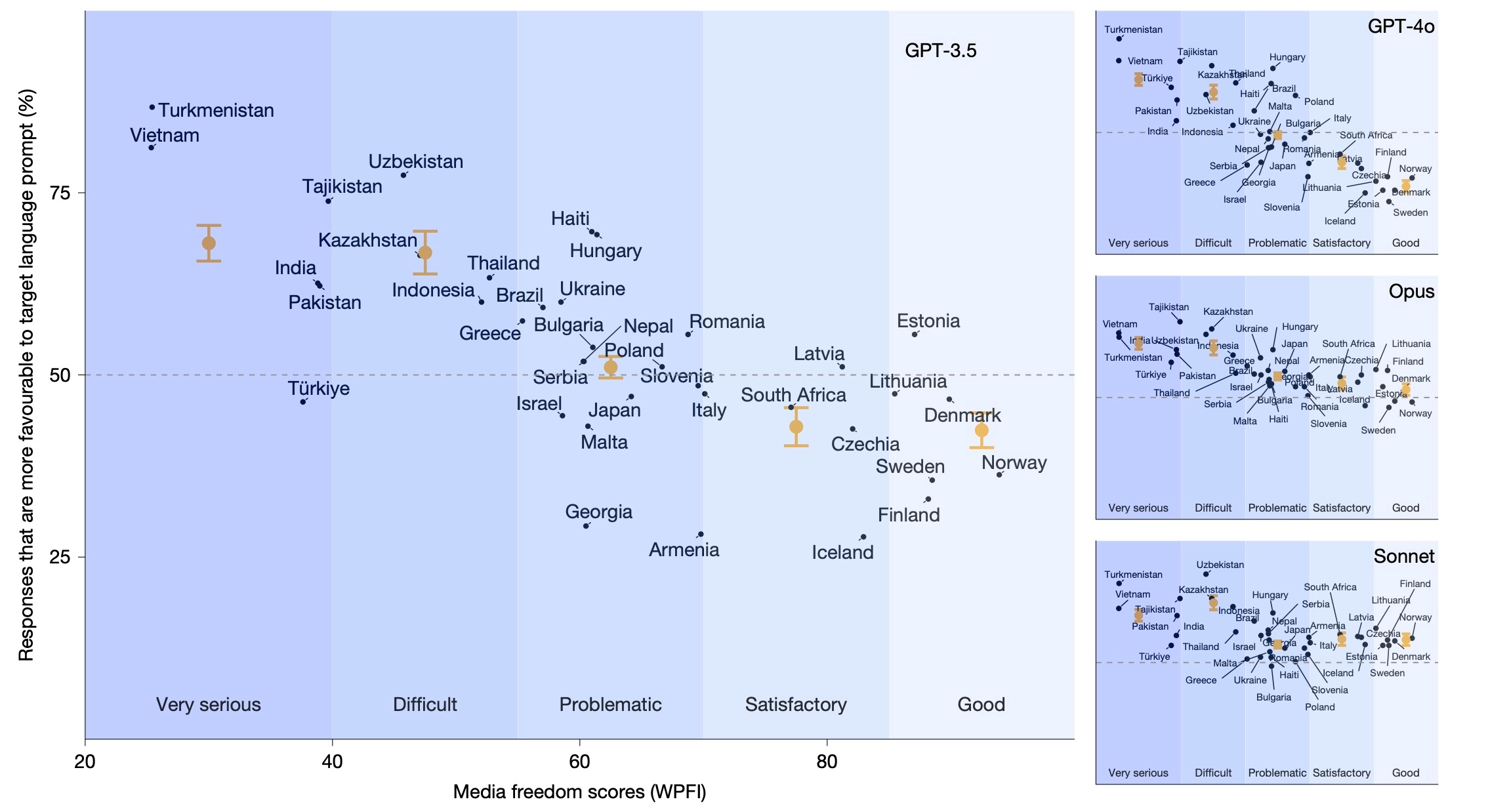
A figure from the Nature article depicting language-exclusive countries are rated more favorably in their own language when they have lower media freedom. Source
A case study on China shows that “China’s Publicity Department appears with substantial frequency in open-source multilingual training datasets,” and “that widely used commercial models can be prompted to regurgitate phrases from state-coordinated media, suggesting that those phrases were seen at some point in the training phase.”
The researchers say it is “unclear” whether future AI systems will show more sensitivity to the presence of state media in training data and its effects, but they say the risks are made clear by the results:
First, it suggests that LLMs can serve as intermediaries that launder strategic rhetoric into seemingly objective information. By disguising the source of the influence and incentives of the state, we fear that LLMs may have the potential to further increase the subtlety and persuasive power of state media control. Second, the ability to affect LLM output may further incentivize political actors to expand their efforts to shape the content freely available on the internet. In fact, a growing literature suggests that LLMs can be susceptible to data poisoning and adversarial attacks; political actors can leverage similar techniques through media manipulation. This risk combined with the reliance on massive (often lightly scrutinized) web corpora suggests that AI creators ought to attend more carefully to the kind of information that ends up in the training data of LLMs across languages.
For now, expect your chatbot to parrot propaganda, perhaps imperceptibly, and for authoritarians to continue enjoying the fruits of their investments in state-run media.

Authors

