
A New Process To Tackle Misinformation On Social Media: Prevalence-Based Gradation
Kamesh Shekar / Jun 28, 2022Kamesh Shekar leads the Privacy and Data Governance vertical at the Dialogue and is a Fellow at The Internet Society.

Introduction
While misinformation and disinformation is not a new threat, it is accelerated by social media platforms. High stakes information like election-related information, health-related information, etc., has critical consequences on individuals and communities in real life.
Presently, the functions of establishing policies around tackling dis/misinformation are distributed across many actors, including social media platforms, governments, users (specifically in the context of decentralized platforms), multistakeholder groups, intergovernmental organizations etc. However, the role of social media platforms themselves in tackling the information disorder needs greater attention, as their intervention poses both questions of competence as well as unintended consequences, potentially causing ill effects like infringing freedom of expression, discretion over dissent etc.
Many centralized and decentralized platforms currently indulge in content-level 'hard' moderation—that is, “only systems that make decisions about content and accounts” as defined by Gorwa et al.—to reduce the spread of misleading/fake information. Platforms use various technological measures like word filters, automated hash-matching, geo-blocking, content IDs, and other predictive machine learning tools to detect unlawful content like child sexual images, pornography, dis/misinformation, etc. Platforms take decisions related to the detected content and account of the individuals using human moderators or algorithms themselves.
These technological measures have their merits to an extent, especially where platforms can act faster and at scale. For instance, Facebook’s transparency report claims that it actioned 95.60% of hate speech before users flagged it (though there is contention on this figure). At the same time, we increasingly see content falling through the crack due to false negatives and getting struck or taken down due to false positives. For instance, despite efforts taken by the social media platforms to flag false information on election integrity, the U.S. Capitol was attacked on 6 January 2021 in part due to the spread of dis/misinformation.
On the other hand, false positives can hamper freedom of expression and opinion. For instance, Facebook famously took down the award-winning image of a naked girl fleeing napalm bombs captured during the Vietnam War. One of the critical reasons posts fall through the cracks is that platforms are presently confined to content-level intervention in the absence of process-level clarity and intervention within the content moderation pipeline. This lack of process-level intervention causes platforms to utilise resources and time inefficiently.
Therefore, the status-quo calls for a proactive and not just reactive content moderation process and means to implement the same efficiently. Against this backdrop, I propose one such process-level intervention that would refine the content moderation pipeline and enable the efficient use of tools and resources across its entirety. While the process-level interventions discussed here can alleviate false negatives and positives through more efficient use of resources, they may not perform any better at eradicating borderline content like mis/disinformation that is highly contextual.
What is Process-level Intervention?
With mounting pressure on the platforms from the government and individuals to tackle narrative harms, they resort to hard content moderation yet face the problem of scale. Scale is less of a problem with soft moderation— “recommender systems, norms, design decisions, architectures”—due to one of the factors, i.e., utilization of data points on individuals to recommend prevalent content which aligns with their preferences. Here the prevalence of the content is not just in terms of popularity but about the ranking of content within the individuals' preferences. When platforms can use the prevalence-based system to determine the real-time ranking and recommendations to the individuals in the form of soft moderation, I propose a “prevalence-based gradation process” – a system that uses prevalence as an integral element for hard moderation to tackle mis/disinformation.
This prevalence-based gradation (PBG) process would act as a means through which social media platforms can evaluate content using ex-ante measures (refer to 2.2) and exercise optimal corrective action in a calibrated format adjusted according to the exposure level of the information. Here the exposure and prevalence level of information is? again, not just about popularity but rather calibrated information bucketing, as discussed in 2.1. Moreover, the PBG process would progressively streamline (discussed below) the existing hard moderation pipeline (refer to figure 1) presently followed by the platforms.
Figure 1: Process-level intervention
2.1. Bucketing Content Based on Prevalence
Currently, platforms follow plain and simple hard content moderation without much granular gradation to efficiently utilize the limited resources at their disposal for more serious concerns. While platforms categorize election-related information, health information, etc., as high-stakes information that needs additional restrictions and scrutiny, within that high-stakes information, platforms typically don’t primarily prioritize content according to the reach and prevalence. This is suboptimal as high-stakes information with two different prevalence levels shouldn’t be treated the same way. Therefore, platforms need to utilize the data collected on the individuals, like followers levels, likes, shares, comments on their content etc., to bucket the information within the gradation matrix. As depicted in Table 1 below, a simple prevalence-based gradation matrix uses data points such as the number of followers, likes, and shares to bucket high-stakes information ranging from high to low levels and chances of prevalence. While the below table is a simple depiction of the prevalence-based gradation matrix, platforms can create a more nuanced and complex matrix with the amount of data they collect.
Table 1: Prevalence-based gradation matrix
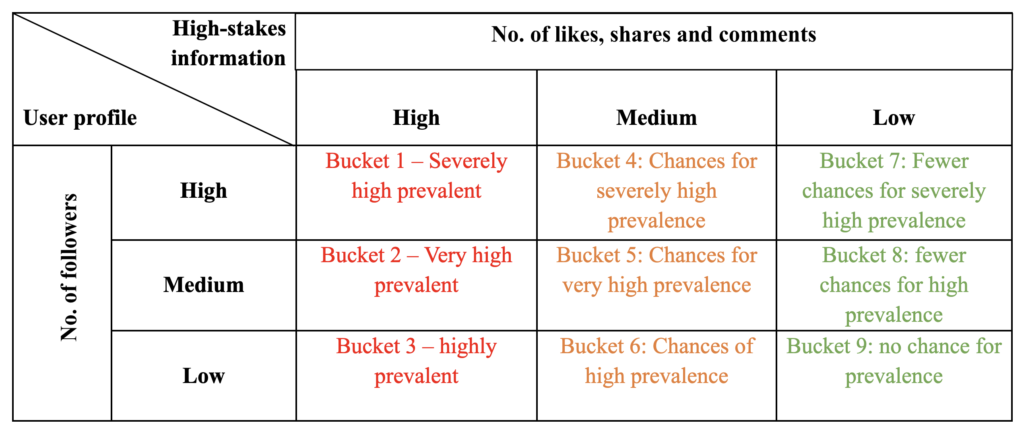
2.2. Evaluating high prevalence information: Ex-ante scrutiny
Ex-ante scrutiny for many social media platforms is to act on the inappropriate content before individuals flag it, or to screen content before the information is made public or shared. This pre-screening of almost every piece of information on the platform is not pragmatic and disproportionate, infringing on the freedom of expression of individuals. However, as the prevalence of the information shared or made public increases, the importance of shared information increases, and so does the responsibility to scrutinize content proportionately. Therefore, instead of traditional pre-screening, it is ideal for platforms to act before harm is caused in a calibrated way, depending on the levels of information prevalence (The proposed model considers this as ‘ex-ante.’)
For instance, information in buckets 1 to 3 from table 1 should be subjected to ex-ante scrutiny, i.e., evaluating the prevalent high-stakes information to find disinformation and misinformation, while the information in buckets 4 to 6 stays on high alert. While it is important to acknowledge that it is difficult to determine whether the information is misleading or fake, however, this process could aid platforms in getting more resources and time to determine the veracity of prevalent high-stakes information, which is more of a concern.
2.3. Responsive Corrective Action: Calibration of Enforcement
Suppose the ex-ante scrutiny of prevalent high-stakes information proves misleading or false. In that case, the platforms must take proportionate corrective actions to control the spread and harm. However, the platforms exercise a limited range of corrective actions that don’t necessarily align with hard moderation enforcement goals, panning out excessively in some instances. For instance, platforms excessively use content takedown, user account blocking and content flagging to achieve almost every hard moderation enforcement goal. Therefore, the platforms must have various corrective actions to align with the different enforcement goals of hard moderation, like a moratorium for deterrence, misleading, etc. The harms to be recognised for corrective action should be tangible, like financial, health repercussions, etc., and intangible, like emotional and psychological, reputational, etc.
Moreover, the causation of harm should not be the only factor for a platform to take action. The corrective actions must be ex-ante (like discussed), i.e. acting before the harm is caused by the prevalent misleading/fake information and, to an extent, speculative, i.e., concerns could arise in the long term like keeping the information in the bucket 4 to 6 in high alert.
Besides, corrective actions must be calibrated such that the information of two different prevalence must be subjected to appropriate corrective action. For instance, information bucket 1 should be treated differently from information in bucket 2 and subsequent buckets. For instance, bucket 3 information can start with the platform flagging and masking the information to be misleading/fake and stop people from sharing it further. As the same information starts moving to bucket 2, more severe actions can be taken.
A Way Forward
Though the intention behind social media platforms instituting technological measures (like the ones mentioned) is to increase accuracy and agility, I posit we increasingly still see the opposite. Therefore, adopting a prevalence-based gradation process by social media platforms is critical. The process will help tackle false negatives, which cuts positive reinforcement for negative behaviour, i.e., posting and sharing misinformation and disinformation. Moreover, it will create a more transparent environment where users understand measures enforced by the platforms according to the prevalence. This process will indirectly aid the platforms in reducing false positives as it would gain them some time and resources to understand the context of the information better. A gradation matrix can also help platforms accomplish efficient utilisation of resources in terms of monitoring content for narrative harms, where they can spend the most time and resources on the issues that are more serious.
However, it is also essential to systematically confront the cons of this process, like whitelisting, i.e. shadowing a particular set of individuals from any moderation, discrimination, i.e. infringing on the voice and dissent of underrepresented individuals etc. Besides, it is also essential to outline the extent to which data points can be used for this process, levels of gradation, threshold and boundaries of the process. Moreover, it is also critical to democratically expand the corrective action tool kit for platforms involving various policy actors in the process to achieve various hard moderation enforcement goals. In addition, the corrective action tool kit to be developed must have a manual for the platforms in terms of how to enforce them in a calibrated fashion depending upon the prevalence of high-stakes information.
Therefore, as we move forward, the platforms must adopt this process or any other process-level intervention to strengthen the foundation that underpins the Internet’s success, i.e., trustworthiness, by intervening in the application layer of the internet. Therefore, this process-level intervention in content moderation to tackle disinformation and misinformation ensures individuals have a trusted and secure internet experience.
Authors

