
A Menu of Recommender Transparency Options
Jonathan Stray, Luke Thorburn, Priyanjana Bengani / Aug 8, 2022Priyanjana Bengani is a Senior Research Fellow at the Tow Center for Digital Journalism at Columbia University; Jonathan Stray is a Senior Scientist at The Center for Human-Compatible Artificial Intelligence (CHAI), Berkeley; and Luke Thorburn is a doctoral researcher in safe and trusted AI at King’s College London.

Recommender systems are ubiquitous, yet there are major unanswered questions about their operation and impact. The users of recommender-based platforms often don’t know why they’re seeing certain items, the public and policy-makers don’t understand how feeds are produced, and the extent to which the “algorithms” can be blamed for societal problems (from teen depression to radicalization to genocide) remains unclear. Platforms have adopted a host of transparency measures, from high-level statistics to APIs, tools, and privacy-protected data sets, but these remain insufficient to understand content selection algorithms and their actual influence on society.
Platforms have pushed back on calls for additional transparency measures citing user privacy concerns, especially in the aftermath of the Cambridge Analytica scandal. There are other legitimate reasons to keep things secret, as certain disclosures might expose trade secrets or compromise system security. Yet much of the resistance to transparency seems to be about avoiding embarrassment. Executives at Meta have voiced concerns that they were “giving away too much [information],” allowing users to dig up data that didn’t reflect well on the company.
This has led to a lively policy discussion around platform transparency, and a variety of proposed legislation that takes different approaches to compelling disclosure for recommender systems. But disclosure of what? To ground this discussion in specifics, we offer a menu of things that recommender “transparency” could mean. This includes UI affordances for individual users, documentation detailing system behavior, anonymized data sets, and research collaborations. We broadly categorize these options into documentation, data, code, and research. Each type of disclosure has its advantages and drawbacks, and each might serve particular purposes for particular groups.
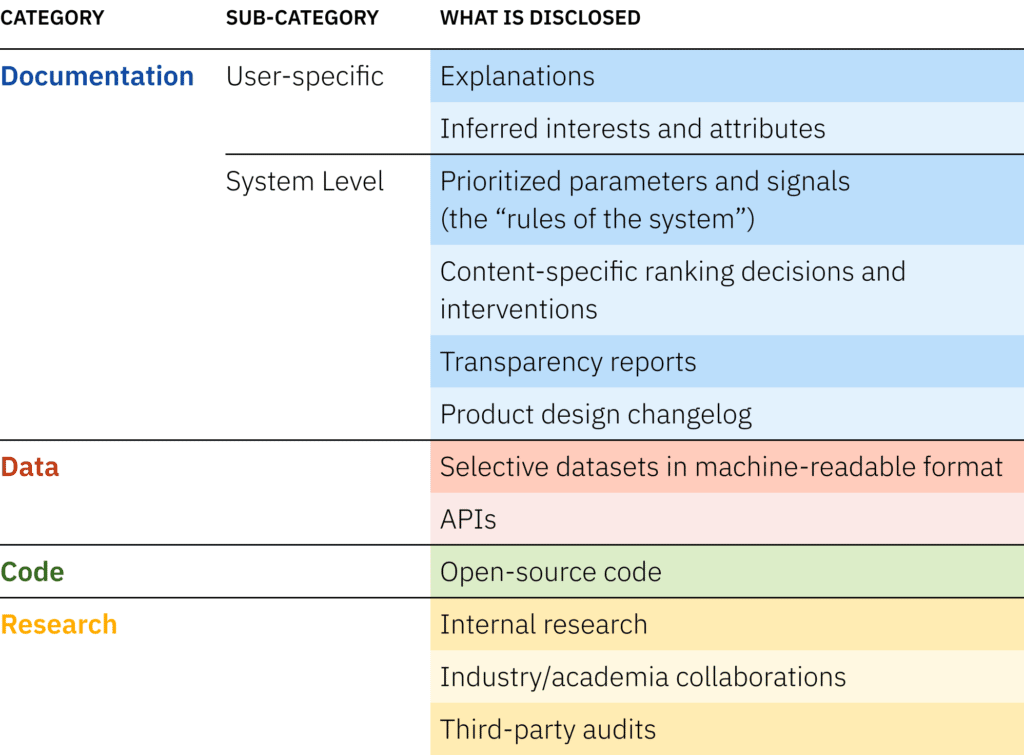
descriptions and examples of each transparency option.
Documentation
Documentation is the simplest form of transparency, where the platform relies on natural language to explain what’s going on to its users and other interested parties. We break this down into user-specific documentation and system-level documentation.
User-specific documentation
Algorithmic feeds are highly dependent on individual user activity and documentation generated for each user can explain why they’re seeing what they’re seeing. Real-world examples include Facebook’s “Why am I seeing this post?” and Amazon’s “Frequently bought together” panel recommending other items to buy. Explainability and transparency are not interchangeable, but transparency is one of the aims of explainability, and transparency measures “should give an honest account of how the recommendations are selected and how the system works.”
This “honest account” should extend to informing the users about the interests(e.g. skiing, black-and-white movies, or bird-watching) and attributes (e.g. race, age, or sexual orientation) that the platform may have inferred about them, including how the system made these inferences. What specific actions taken by the user led to a given inference? If user behavior was combined with off-platform activity, how was the data obtained? This level of disclosure would also help address both the “Why” questions users are likely to ask when they don’t understand the reasons a specific post is shown (e.g. the case of a user who saw an ad on his feed asking, "COMING OUT? NEED HELP?”), and the “Why Not” questions when they expect certain results that the recommender system does not produce. Creating additional UI affordances to let users rectify incorrect or unwanted inferences can also ensure users have more control over their online experience.
System-level Documentation
Beyond individual users, ranking decisions applicable to the entire recommender system should be documented. Such documentation could be modeled on existing transparency reports that provide high-level information on requests from law enforcement and government, the number of content takedowns for different reasons, and various security and integrity initiatives.
These are important numbers, but they do not provide any information about algorithm design. Additional documentation could include the types of content the platform prioritizes and downranks, and whether it is operating under heightened “break-glass” conditions due to external factors like elections or other events likely to increase civic unrest. Customers should also be informed if a platform is prioritizing its own brands or partners. Advocacy groups have suggested publicly logging all major changes made to the system, including technical adjustments, new features, and changes in policy.
Documentation does not necessarily allow for independent oversight. Further, it will remain difficult to understand how recommenders and their effects differ across regions or demographic groups. Providing deeper access to data is one way to address these deficiencies.
Data
To understand what is happening on a platform – including what a recommender algorithm is doing – it is necessary to have data on what users are seeing and how they are responding. Twitter regularly releases datasets containing tweets and account details related to state-linked information operations, while Facebook has released a large dataset of URLs in partnership with the Social Science One academic consortium. (However, this data set was plagued with delays and ended up missing data from roughly half of Facebook’s US users.)
Another approach, application programming interfaces (APIs), provide ongoing access to platform data. This includes tools like Facebook’s CrowdTangle (which allows approved users and institutions to access data about public Facebook and Instagram accounts) and Twitter’s Developer API (which gives approved users programmatic access to public tweets, among other things). Platforms can provide interfaces for journalists, researchers, academics and other vetted stakeholders to access additional data.
Researchers have frequently called for access to platform data that is not currently public. Some common categories of data requested include reliable access to historical data (e.g. what items have trended on Twitter or Reddit historically?), impressions alongside engagements (i.e. how many people saw a piece of content irrespective of whether they interacted with it), and access to longitudinal data that allows user behavior to be (anonymously) traced over time.
One of the major challenges to wider data disclosures is the tension between transparency and privacy. From 2010 to 2015, before the Cambridge Analytica scandal, Facebook’s Graph API effectively provided an all-access pass where developers didn’t require consent from a user’s friends to collect their profile data. Since then, APIs have become more stringent. In 2018 Twitter tightened their developer application process to include “case reviews and policy compliance checks.” These sorts of restrictions provide important privacy protections, but privacy can also be used as an excuse to avoid disclosure.
There are numerous strategies that help meet privacy obligations while releasing large datasets, including differential privacy which strategically adds noise to aggregated data to prevent the re-identification of individuals. However, there are concerns that this intentional randomness may make it difficult to replicate prior research. Typically, researchers do not need to identify individual behavior, and even trusted parties probably shouldn’t have access to data about individual people. At the same time, there is a need for information about aggregate behavior in different contexts, say for different subgroups of people in different geographies. This kind of data should allow outsiders to determine which areas of the platform to focus on, consider who is benefitting from the system, and assess which user groups are underserved.
Despite the potential benefits of increased transparency, in many ways platforms have been releasing less data, not more. In the last two years, Facebook has hamstrung CrowdTangle's development with an eye to scrapping the project entirely and moving towards even more selective disclosures. Researchers and journalists have been forced to develop their own transparency tools, such as browser extensions that allow users to donate their data, or bot-based simulations that attempt to reverse-engineer algorithmic behavior. Platforms can block these third-party tools or claim that they violate their policies and shut them down, which leaves the public worse off. Companies have also dismissed findings by arguing that outside researchers relied on incomplete datasets – which is often true, and is exactly the problem that greater transparency aims to solve.
Code
Open-sourcing recommender code could be useful, but not in isolation. Real recommender systems are complex, and there isn’t a single algorithm that underpins the whole system. Rather, different machine learning models trained on different data sets perform a variety of functions within the system. Even the core ranking code (perhaps the value model that is used to compute a score for each item) will not explain very much without detailed data on actual user behavior on the platform, because recommender outcomes are always a combination of human and machine behavior. For example, a high weight on content of a particular type doesn’t necessarily mean a user will see a lot of it, as exposure depends on many other factors including how much of that type of content is produced by other users. Open-sourcing the code might also help bad actors figure out how they can better manipulate the system.
Few platforms offer much in the way of source code transparency. Reddit was open-sourced back in 2008 when it first launched, but eventually stopped updating its public repository. Twitter’s Birdwatch, a crowd-sourced fact checking initiative, has open-sourced its “note ranking” code, but this is a minor, experimental initiative. In the absence of such transparency measures, outsiders must resort to combing through blog posts or public academic papers, which may provide high-level descriptions of algorithms.
Research
Platforms are constantly running a slew of internal research projects and testing different approaches to their recommendation systems. The results of such experiments are not typically announced in press releases, but sometimes do appear in papers submitted to conferences (or leaks, as in this 100,000 user Instagram study of social comparison). These studies can provide greater insight into what a platform is working on, the psychological effects of platform use, unintended bias observed in content ranking and mitigation methods to reduce it. In the absence of publicly-available data, it’s impossible to verify or replicate these findings.
More recently, there have been conscious efforts in building collaborative efforts between industry and academia. A Twitter partnership with OpenMined aims to advance algorithmic transparency by releasing privacy-protected datasets that would allow anyone to replicate certain internal research. Another example is Facebook’s partnership with academics to better understand discourse during the 2020 election. These projects are still nascent, and the extent to which they promote real transparency is yet to be seen. In principle, these sorts of collaborations could go well beyond data access by providing external researchers the ability to design and conduct experiments on a platform. This is essential because many of the more pressing questions are causal in nature and cannot be answered by data alone.
Finally, audits can be considered a particular kind of structured “research” conducted by outside parties. At the moment there are no good examples of completed recommender system audits (Facebook recently released an independent assessment of its community standards enforcement, but this is not a recommender audit). However, the proposed text of the recently-passed Digital Services Act requires large platforms to allow external audits of “content moderation systems, recommender systems and online advertising.” Audits could be initiated by the company themselves or as part of regulatory oversight, and auditors would have more extensive access than outside researchers and journalists. This could include access to internal code and configurations, clean room access to user data, and separate APIs that allow monitoring system behavior over time.
There are many possible goals of recommender system audits. The Digital Services Act requires audits to assess the “protection of public health, minors, civic discourse, or actual or foreseeable effects related to electoral processes and public security” but does not say how this is to be accomplished or what standards to apply. There are more detailed proposals for auditing discrimination, polarization, and amplification in recommender systems.
In principle, one could assess any of the potential harms discussed above, though many harms would require experiments to assess, stretching the meaning of “audit.” More broadly, audits have the potential to verify whether the design and operation of a recommendation system adheres to best practices and does what a company says it does. Performed well, audits could provide most of the benefits of open-source code and user data access, without requiring either to be made public. However, legally required audits are unlikely to address all areas of concern to external stakeholders.
A Range of Options
Researchers, policy-makers, and journalists have long implored platform companies to be more transparent, including around the core algorithms used to select and personalize content. In the absence of substantive improvements, regulatory authorities globally are putting forward legislative proposals with broadly-worded requirements for algorithmic transparency. Yet it’s not obvious what “transparency” actually means for such large and complex systems where outcomes are the result of interactions between algorithms and people. Four categories of transparency measures — documentation, data, code, and research — can each provide unique insights into what the algorithms we interact with every day are actually doing.
Authors



